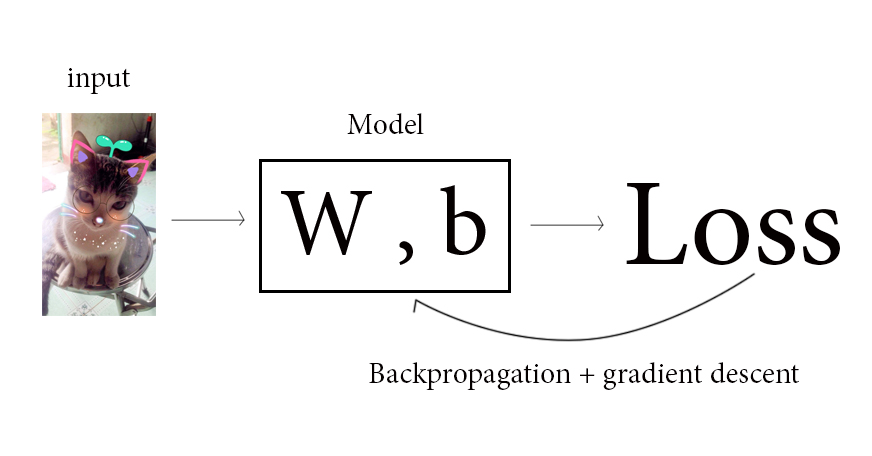
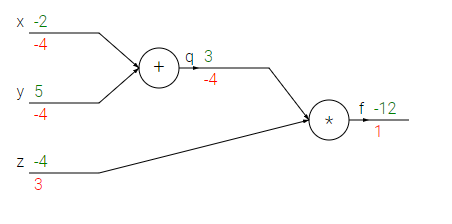
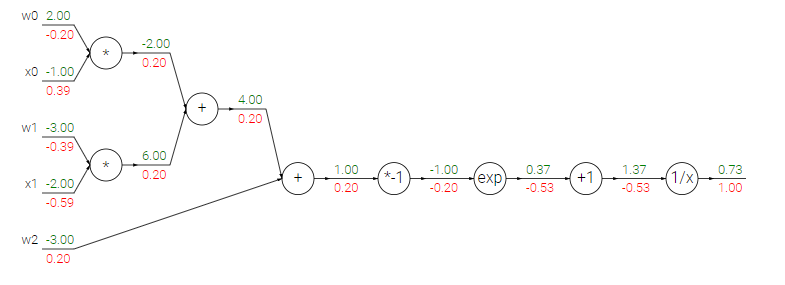
Chào mừng bạn đến với các bài học Image classification, một trong những bài học thuộc mảng Computer Vision được mình viết trên blog cá nhân. Mong rằng qua những bài học trong series này, bạn sẽ nắm vững được một số kiến thức cơ bản trong việc phân loại hình ảnh sử dụng các phương pháp máy học, để từ đó có thể làm tiền đề cho những ứng dụng sau này của bản thân.
Bài 1 : Giới thiệu
Bài đầu tiên sẽ giới thiệu tổng quan về series image classification.
Bài 2 : Image classification
Bài này sẽ giới thiệu tổng quan về image classification
Bài 3 : Thuật toán Nearest Neighbor Classifier
Thuật toán phân lớp Người láng giềng gần nhất
Bài 4 : Cài đặt Nearest Neighbor Classifier với ngôn ngữ Python
Bài 5 : Thuật giải K-Nearest Neighbor
Bài 6 : Cài đặt K-Nearest Neighbor Classifier với ngôn ngữ Python
Bắt đầu từ đây, các bài tiếp theo sẽ dính dáng khá nhiều tới toán học nhé mấy man. Nếu không hiểu công thức toán thì cứ kệ đi nhá :v Vì biết đâu đọc ví dụ lại hiểu. Đó cũng là cách mình đọc tài liệu ( vì mình không giỏi toán lắm).
Bài 7 : Score function
Bài 8 : Loss function
Bài 9: Optimization và Gradient Descent
Bài 10: Backpropagation
Bài 11: Giải thích quá trình máy học
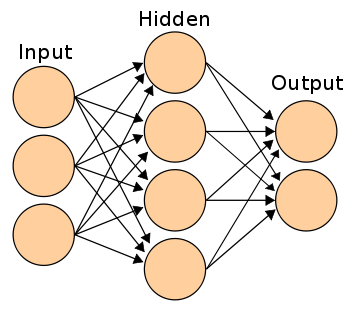
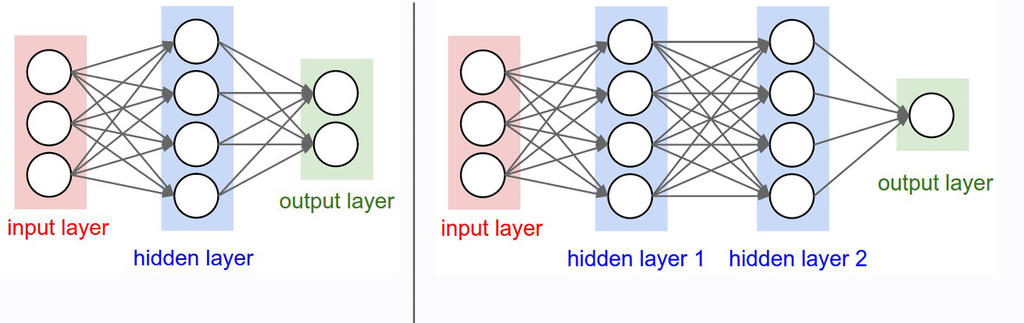
Như vậy, chúng ta đã hiểu máy học là gì. Những phần tiếp theo, chúng ta sẽ tìm hiểu về model. Những model được đem vào mổ sẻ là ANN (mạng nơ ron nhân tạo) và CNN (mạng nơ ron tích chập).
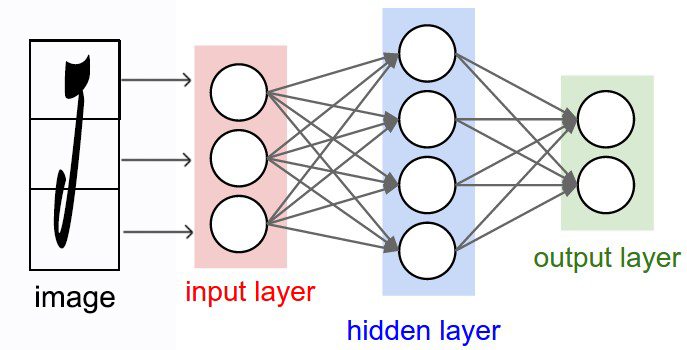
Bài 12: Kiến trúc mạng neural nhân tạo
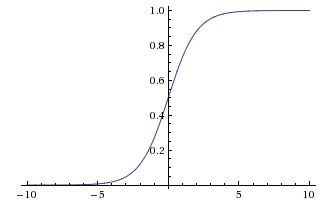
Bài 13: Cấu trúc của 1 neural
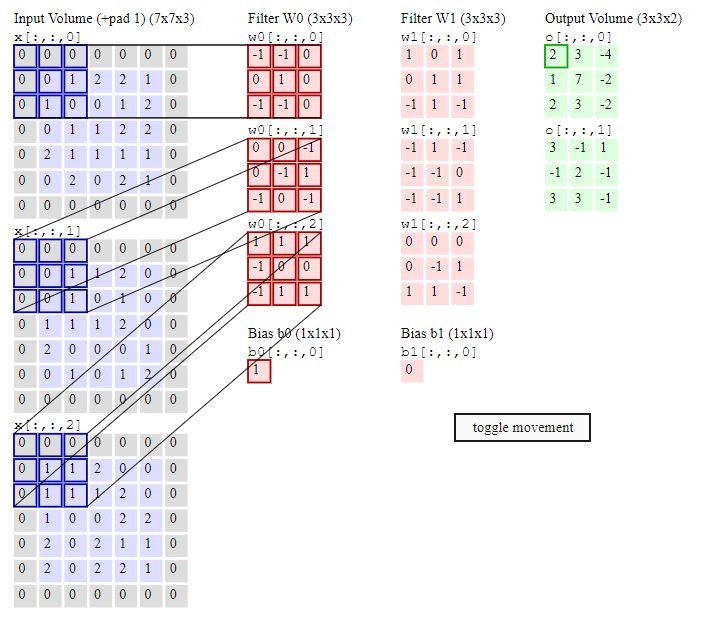
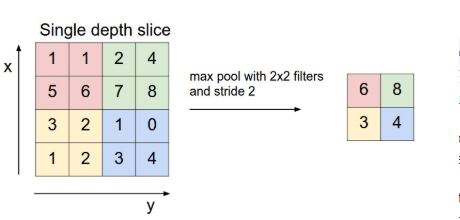
Bài 14: Tìm hiểu mạng CNN
Okie, Vậy là chúng ta đã hoàn thành được bài CNN, cũng là bài cuối trong loạt series image classification của mình. Đây chỉ là kiến thức nền cơ bản để các bạn hiểu và nắm được các khái niệm của Classification và những mạng model dùng để giải quyết bài toán đó. Mong các bạn dựa vào đây có thể tự mình tìm hiểu và phát huy được bản thân trong lĩnh vực đầy thú vị này. Chào thân ái và quyết thắng.
 Chào mừng bạn đến với các bài học Image classification, một trong những bài học thuộc mảng Computer Vision được mình viết trên blog cá nhân. Mong rằng qua những bài học trong series này, bạn sẽ nắm vững được một số kiến thức cơ bản trong việc phân loại hình ảnh sử dụng các phương pháp máy học, để từ đó có thể làm tiền đề cho những ứng dụng sau này của bản thân.
Chào mừng bạn đến với các bài học Image classification, một trong những bài học thuộc mảng Computer Vision được mình viết trên blog cá nhân. Mong rằng qua những bài học trong series này, bạn sẽ nắm vững được một số kiến thức cơ bản trong việc phân loại hình ảnh sử dụng các phương pháp máy học, để từ đó có thể làm tiền đề cho những ứng dụng sau này của bản thân.Bài 1 : Giới thiệu
Bài đầu tiên sẽ giới thiệu tổng quan về series image classification.
Bài 2 : Image classification
Bài này sẽ giới thiệu tổng quan về image classification
Bài 3 : Thuật toán Nearest Neighbor Classifier
Thuật toán phân lớp Người láng giềng gần nhất
Bài 4 : Cài đặt Nearest Neighbor Classifier với ngôn ngữ Python
Bài 5 : Thuật giải K-Nearest Neighbor
Bài 6 : Cài đặt K-Nearest Neighbor Classifier với ngôn ngữ Python
Bắt đầu từ đây, các bài tiếp theo sẽ dính dáng khá nhiều tới toán học nhé mấy man. Nếu không hiểu công thức toán thì cứ kệ đi nhá :v Vì biết đâu đọc ví dụ lại hiểu. Đó cũng là cách mình đọc tài liệu ( vì mình không giỏi toán lắm).
Bài 7 : Score function
Bài 8 : Loss function
Bài 9: Optimization và Gradient Descent
Bài 10: Backpropagation
Bài 11: Giải thích quá trình máy học
Như vậy, chúng ta đã hiểu máy học là gì. Những phần tiếp theo, chúng ta sẽ tìm hiểu về model. Những model được đem vào mổ sẻ là ANN (mạng nơ ron nhân tạo) và CNN (mạng nơ ron tích chập).
Bài 12: Kiến trúc mạng neural nhân tạo
Bài 13: Cấu trúc của 1 neural
Bài 14: Tìm hiểu mạng CNN
Okie, Vậy là chúng ta đã hoàn thành được bài CNN, cũng là bài cuối trong loạt series image classification của mình. Đây chỉ là kiến thức nền cơ bản để các bạn hiểu và nắm được các khái niệm của Classification và những mạng model dùng để giải quyết bài toán đó. Mong các bạn dựa vào đây có thể tự mình tìm hiểu và phát huy được bản thân trong lĩnh vực đầy thú vị này. Chào thân ái và quyết thắng.