Dẫm chân vào lĩnh vực máy học, ai cũng phải đạp qua 1 khái niệm gọi là: OverFitting (tiếng việt là : "khít quá!!!"). Vậy Overfitting là gì? Tại sao lúc nào khái niệm này cũng xuất hiện và ám ảnh người học đến thế? Bài này sẽ giúp bạn có cái nhìn tổng quát về vấn đề này.
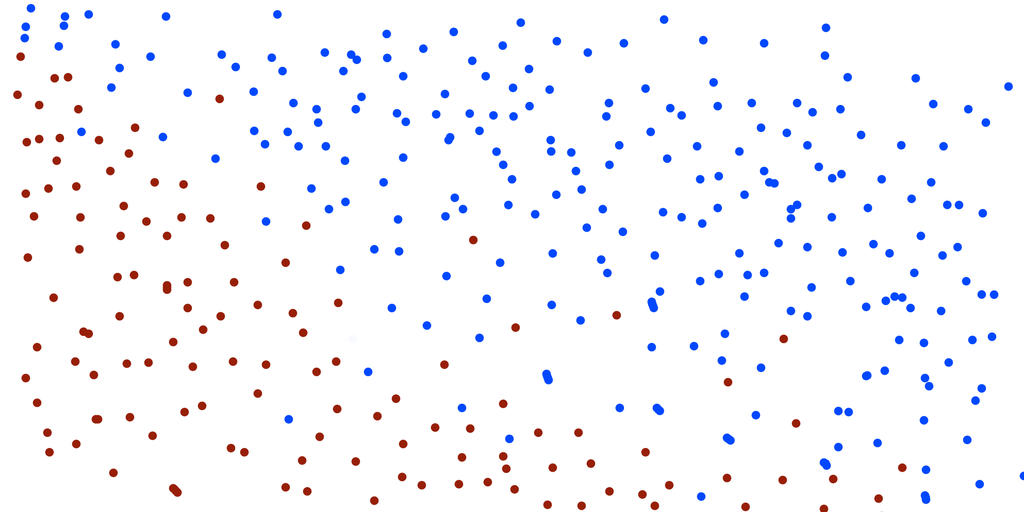
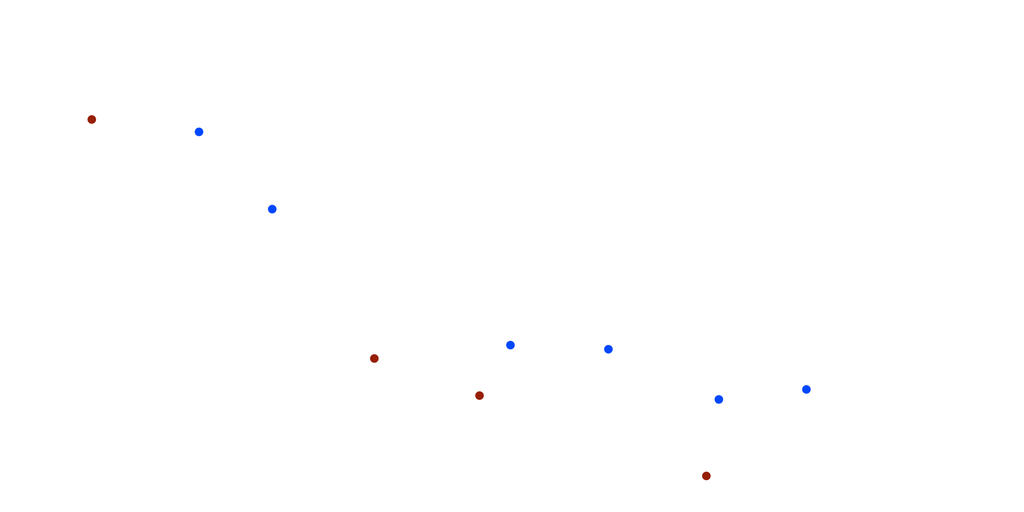
Chúng ta cùng xem xét 2 tập dữ liệu dưới đây:
Tập training set
Tập testing set
Nhiệm vụ của bạn bây giờ là xây dựng 1 mô hình để gán màu cho tập testing set. Thông thường, với các phương pháp máy học, mô hình sẽ được xây dựng dựa trên sự sai số khi dự đoán trên tập train. Mô hình sẽ được cập nhật với tiêu chí sao cho độ lỗi khi dự đoán càng ngày càng nhỏ dần, điều này đồng nghĩa với mô hình dự đoán càng ngày càng chính xác. Giả sử sau 1 ngày học, máy tính đưa ra được 1 đường phân chia màu cho tập training set như sau.
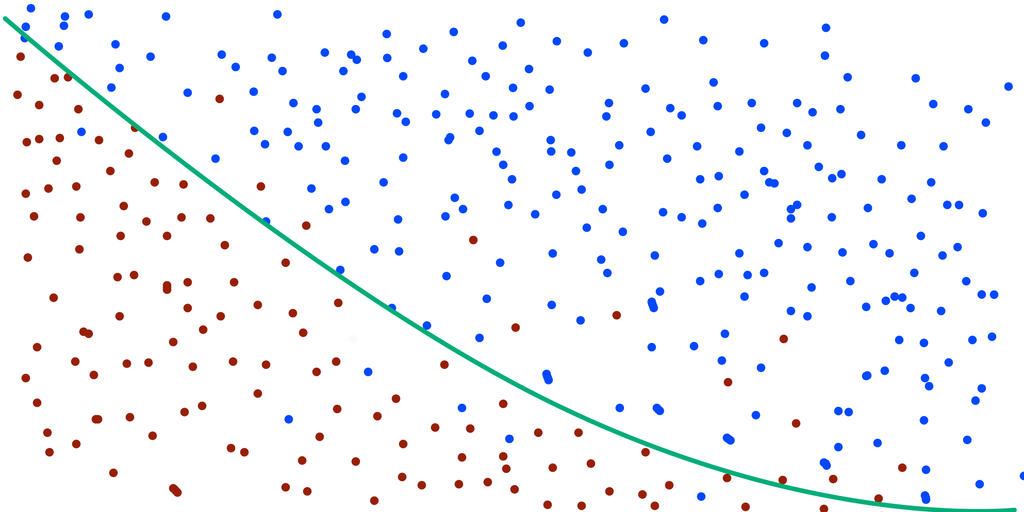
Bạn có thể thấy, mô hình này vẫn chưa dự đoán đúng được hết. Vẫn còn một số điểm được phân loại sai. Vậy nên, bạn quyết định cho máy học thêm 1 ngày nữa. Và kết quả thật bất ngờ, bạn có 1 đường phân chia không sai một mili nào.
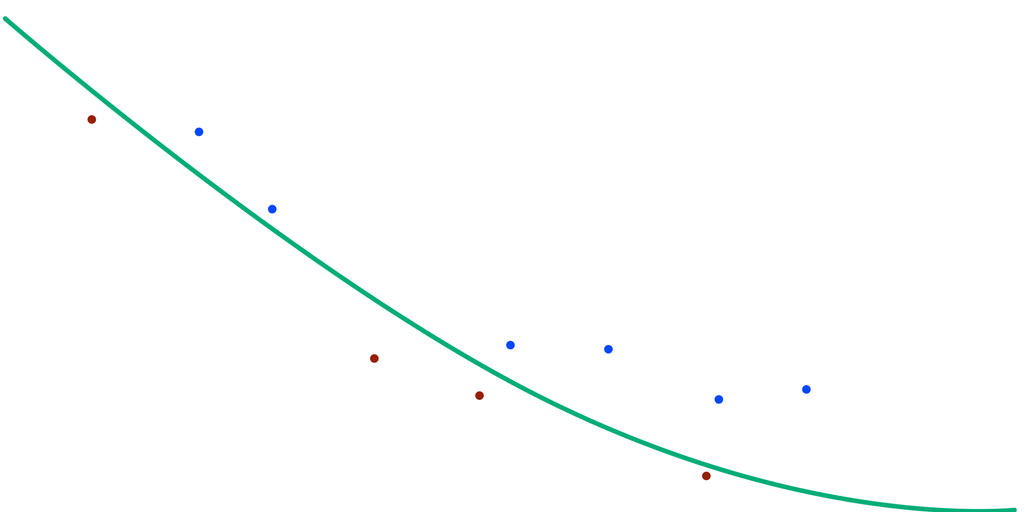
Thật tự hào đúng không? độ lỗi của mô hình máy học bây giờ đã là 0% trên tập training set. Một mô hình tuyệt vời, gán màu không sai 1 điểm nào. Và bạn nghĩ chắc chắn mô hình này cũng sẽ cho kết quả thật tuyệt vời trên tập testing set. Nhưng, đời không như là mơ ( và cũng vì lí do đó nên đời hay giết chết mộng mơ). Mô hình đỉnh cao của bạn chỉ đạt 30% độ chính xác trên tập testing set. :'( Nhưng ngạc nhiên hơn, mô hình đầu tiên mà bạn có (mô hình có độ lỗi sau 1 ngày máy học) , lại cho ra kết quả gán màu chính xác 100% trên tập testing set. Thật không thể tin nổi. Tại sao lại như vây, chuyện gì đang xảy ra. Và đây là thời khắc bạn nhận ra, bạn đã dẫm phải một khái niệm có tên là Overfitting.
Overfitting là hiện tượng mô hình dự đoán quá khớp với tập training set, dẫn đến dự đoán không hiệu quả đối với tập testing set.
Ok, đó là khái niệm khái quát nhất mà khi đọc vào bạn chả hiểu gì. Vậy thì hãy xem lại 2 mô hình trên một lần nữa. Với mô hình thứ 1, mặc dù độ chính xác trên tập training set không quá tối ưu, nhưng lại đạt 100% chính xác trên tập test.
Với mô hình thứ 2, đạt tối ưu 100% trên training set và chỉ đạt 30% trên testing set.
Bạn đã hiểu ra rồi chứ? Vì đường phân chia quá khớp với tập train, nên khi đưa một tập khác vào để dự đoán (tập test) thì kết quả sẽ sai lệch nhiều. Và đây chính là overfitting. Vì vậy, khi bạn đưa ra 1 mô hình dự đoán với sai số 0% trên tập train, đừng tự hào vỗ ngực vội! Vì có thể một mô hình với độ sai lệch 20% trên tập train lại cho ra kết quả dự đoán trên tập test cao hơn bạn đấy!



Thật dễ hiểu! Cám ơn bạn :D
Trả lờiXóacảm ơn bạn!
Trả lờiXóalike. Bạn giải thích rất dễ hiểu!!!!!!!!!!!!!!!
Trả lờiXóacám ơn tất cả mọi người đã ghé đọc bài viết của mình nha.
Trả lờiXóaủa vậy thì làm sao biết được độ chính xác ở tập train là như nào để cũng tương xứng với tập test?
Trả lờiXóanếu 90% là độ chính xác tập train?
làm sao để kiểm soát nó cũng chính xác với tập test ạ
người ta khi train thì sẽ thử kết quả trên tập validation bạn nhé (nếu chưa biết validation là gì thì bạn xem thêm bài https://cuonglv1109.blogspot.com/2018/11/trong-may-hoc-co-mot-khai-niem-ma-tat.html ). Người ta ngầm cho rằng validation mà có độ chính xác cao thì tập test cũng có độ chính xác cao, do đó quá trình training chủ yếu sẽ dựa trên kết quả của tập validation chứ không phải tập training.
XóaUây, đúng hài luôn á. Đơn gioản, dễ hểu
Trả lờiXóacảm ơn giải thích của bạn, thật đơn giản và dễ hiểu.
Trả lờiXóa