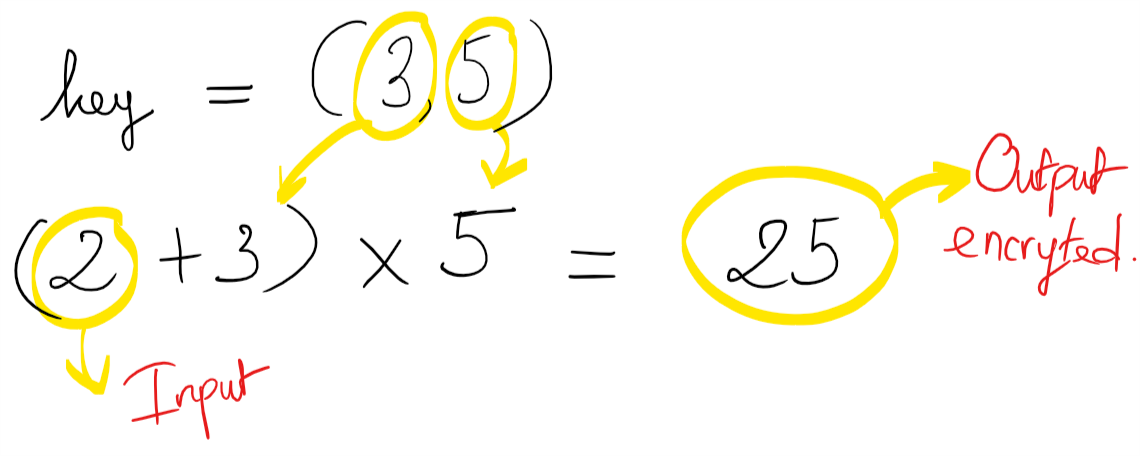Trong bài này, chúng ta đã được tìm hiểu symmetric encryption là gì, asymmetric encryption là gì rồi. Nhưng chúng ta vẫn chưa biết được, làm thế nào để người ta có thể tạo ra bộ key mã hóa và giải mã.
Trong bài hôm nay, mình sẽ giới thiệu cho các bạn 1 trong những thuật toán asymmetric được sử dụng để tạo ra cặp key mã hóa và giải mã. Đó chính là RSA Algorithm.
Rivest–Shamir–Adleman (RSA) là một thuật toán mã hóa bất đối xứng. Sỡ dĩ nó có tên như vậy là vì nó được ghép từ tên của 3 người tác giả.
Bước 1: chọn ra 2 con số nguyên tố tùy ý. 2 con số này chính là p và q. Ví dụ mình chọn p = 2 và q = 7

Bước 2: Tìm N theo công thức: N = p*q . Lúc này, ta có N = 2*7 = 14.

Bước 3: Tính $\phi(N)$ . $\phi(N)$ là hàm phi. Hàm phi của một số nguyên dương N là số các số nguyên dương nhỏ hơn N và là sô nguyên tố cùng nhau với N.Hai số được gọi là số nguyên tố cùng nhau khi mà chúng có ước số chung lớn nhất là 1.
Ví dụ: $\phi(14)=6$ vì từ 1 đến 13, ta có các số 1, 3, 5, 7, 9, 11, 13 là các số nguyên tố cùng nhau với 14. Và số lượng các số này = 6.

Nhưng thực ra, người ta đã chứng minh được một công thức đơn giản hơn để tìm $\phi(N)$, đó là:
$\phi(N)=(p-1)(q-1)$

Bước 4: Tìm số e. Số e là số được tìm sao cho thõa mãn:

Bước 5: tìm d sao cho thõa mãn công thức:
$de(mod\phi(N))=1$
Theo công thức trên, ta có : d*5mod6=1 . Vậy ta có d có thể là 5, 11, 17 ... Ở đây mình chọn d = 11.

Vậy là ta đã tìm được 5 con số quan trọng của thuật toán RSA. Từ 5 con số này, ta sẽ tạo ra được 2 key. Một key dùng để mã hóa (encrypt key) và một key dùng để giải mã (decrypt key).
Encrypt key được tạo nên bởi cặp số (e,N) . Tức là encrypt key = (5,14). Decrypt key lại được tạo nên bởi cặp số (d,N). decrypt key = (11,14).

Việc dùng 2 cặp key này để mã hóa và giải mã như thế nào. Bạn hãy xem lại phần mã hóa bất đối xứng mình đã viết trong bài này nhé.
Bạn hãy để ý, toàn bộ quá trình tạo nên encrypt key và decrypt key đều từ 2 con số q và p. Mà N=p*q. Vậy thì hacker chẳng phải dễ dàng đoán ra được p và q hay sao?????
Ví dụ N =14. Hacker có thể dễ dàng đoán ra được cặp số ngyên tố 2 và 7. Và từ đây, hacker có thể dễ dàng tái tạo được 2 key theo như 5 bước ở trên. Vậy tại sao RSA lại bảo mật được???

Lí do rất đơn giản. Trong thực tế, khi người ta chọn 2 số q và p, thì 2 số này là 2 con số cực kì lớn. Do đó, N cũng là 1 con số siêu to khổng lồ. Và để tìm ra được 2 số nhân với nhau để cho ra N, máy tính phải mất rất rất nhiều thời gian để có thể tìm ra được. Đây là lí do khiến cho hacker không thể truy ra được 2 key mặc dù đã có sẳn N.
Trong bài hôm nay, mình sẽ giới thiệu cho các bạn 1 trong những thuật toán asymmetric được sử dụng để tạo ra cặp key mã hóa và giải mã. Đó chính là RSA Algorithm.
Rivest–Shamir–Adleman (RSA) là một thuật toán mã hóa bất đối xứng. Sỡ dĩ nó có tên như vậy là vì nó được ghép từ tên của 3 người tác giả.
RSA hoạt động như thế nào?
RSA hoạt động dựa vào việc tìm kiếm 5 con số quan trọng: p ,q , N, e và d. Để tìm được 5 con số này, bạn cần thực hiện các bước sau:Bước 1: chọn ra 2 con số nguyên tố tùy ý. 2 con số này chính là p và q. Ví dụ mình chọn p = 2 và q = 7

Bước 2: Tìm N theo công thức: N = p*q . Lúc này, ta có N = 2*7 = 14.

Bước 3: Tính $\phi(N)$ . $\phi(N)$ là hàm phi. Hàm phi của một số nguyên dương N là số các số nguyên dương nhỏ hơn N và là sô nguyên tố cùng nhau với N.Hai số được gọi là số nguyên tố cùng nhau khi mà chúng có ước số chung lớn nhất là 1.
Ví dụ: $\phi(14)=6$ vì từ 1 đến 13, ta có các số 1, 3, 5, 7, 9, 11, 13 là các số nguyên tố cùng nhau với 14. Và số lượng các số này = 6.

Nhưng thực ra, người ta đã chứng minh được một công thức đơn giản hơn để tìm $\phi(N)$, đó là:
$\phi(N)=(p-1)(q-1)$

Bước 4: Tìm số e. Số e là số được tìm sao cho thõa mãn:
1 < e <$\phi(N)$
e là số nguyên tố cùng nhau với N
e là số nguyên tố cùng nhau với $\phi(N)$
Vậy ta có e = 5

Bước 5: tìm d sao cho thõa mãn công thức:
$de(mod\phi(N))=1$
Theo công thức trên, ta có : d*5mod6=1 . Vậy ta có d có thể là 5, 11, 17 ... Ở đây mình chọn d = 11.

Vậy là ta đã tìm được 5 con số quan trọng của thuật toán RSA. Từ 5 con số này, ta sẽ tạo ra được 2 key. Một key dùng để mã hóa (encrypt key) và một key dùng để giải mã (decrypt key).
Encrypt key được tạo nên bởi cặp số (e,N) . Tức là encrypt key = (5,14). Decrypt key lại được tạo nên bởi cặp số (d,N). decrypt key = (11,14).

Việc dùng 2 cặp key này để mã hóa và giải mã như thế nào. Bạn hãy xem lại phần mã hóa bất đối xứng mình đã viết trong bài này nhé.
Tại sao RSA bảo mật?
Theo như cách hoạt động của encrypt key và decrypt key, thì 1 trong 2 sẽ là public key ( khái niệm public key và private key mình đã viết trong bài này). Có nghĩa là, hacker có thể biết được giá trị N.Bạn hãy để ý, toàn bộ quá trình tạo nên encrypt key và decrypt key đều từ 2 con số q và p. Mà N=p*q. Vậy thì hacker chẳng phải dễ dàng đoán ra được p và q hay sao?????
Ví dụ N =14. Hacker có thể dễ dàng đoán ra được cặp số ngyên tố 2 và 7. Và từ đây, hacker có thể dễ dàng tái tạo được 2 key theo như 5 bước ở trên. Vậy tại sao RSA lại bảo mật được???

Lí do rất đơn giản. Trong thực tế, khi người ta chọn 2 số q và p, thì 2 số này là 2 con số cực kì lớn. Do đó, N cũng là 1 con số siêu to khổng lồ. Và để tìm ra được 2 số nhân với nhau để cho ra N, máy tính phải mất rất rất nhiều thời gian để có thể tìm ra được. Đây là lí do khiến cho hacker không thể truy ra được 2 key mặc dù đã có sẳn N.