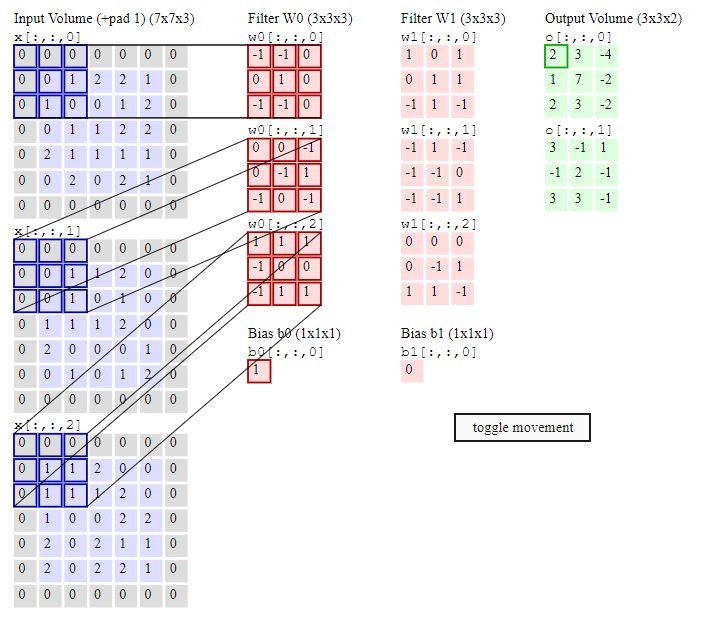
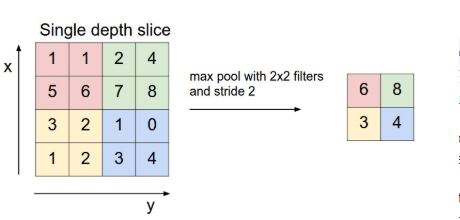
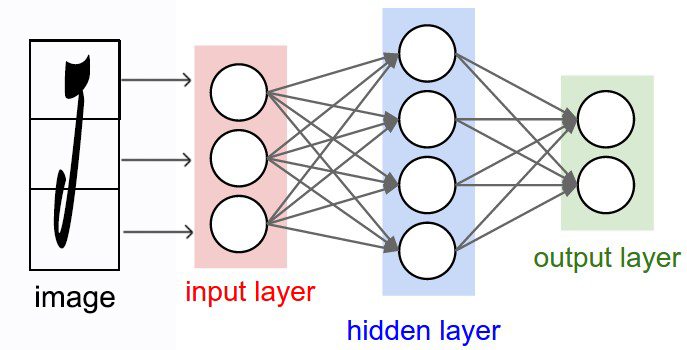
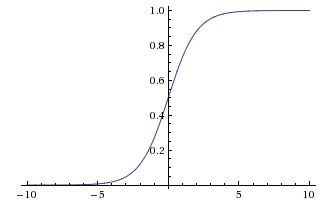
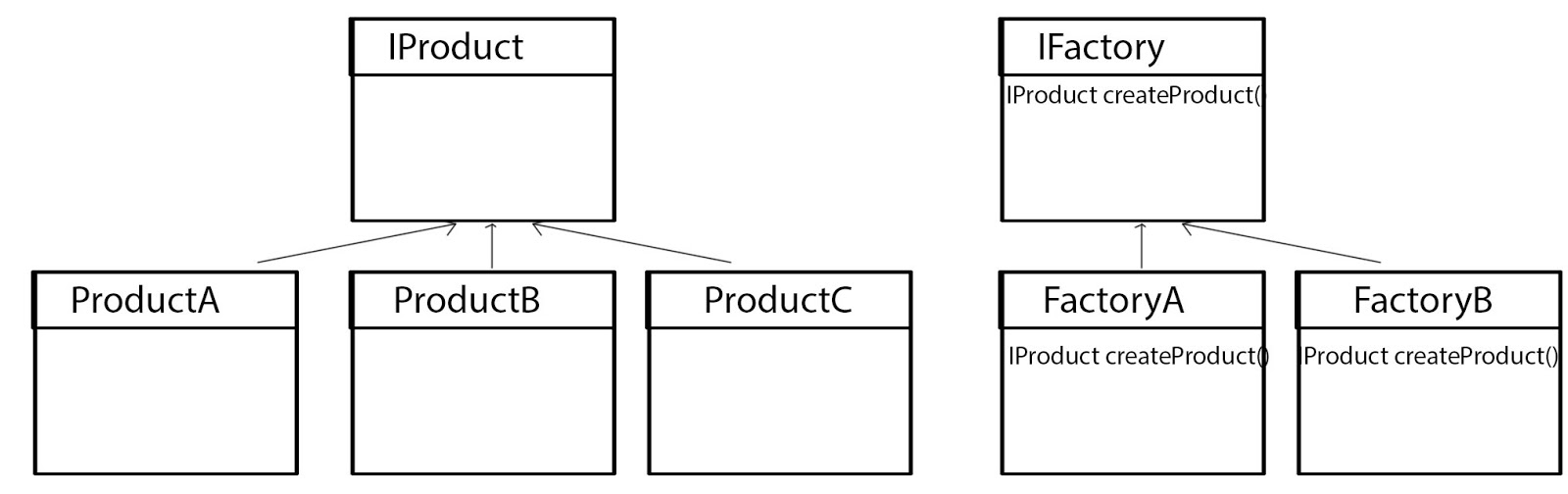
Đây là 1 pattern rất dễ, cái khó nhất có lẽ là đọc cho đúng tên pattern. =)) Facade không đọc là "pha cây" , đọc đúng phải là "phờ sát" (fəˈsɑːd).
oke. Vậy pattern này là gì. Đơn giản lắm! Bạn thử tưởng tượng trong quá trình bạn code, bạn sẽ phân chia các class khác nhau. Theo thời gian thì sẽ có rất nhiều class khác nhau, và các class này sẽ tương tác qua lại với nhau. Điều này thật sự rất rối rắm. Và để giảm bớt sự rối rắm này, Facade pattern được áp dụng vào. Nó sẽ tạo ra 1 lớp Facade bao bọc bên ngoài, và xử lý những kết nối rối rắm dùng chúng ta.
Và để giảm bớt sự rối rắm này, Facade pattern được áp dụng vào. Nó sẽ tạo ra 1 lớp Facade bao bọc bên ngoài, và xử lý những kết nối rối rắm dùng chúng ta.

Đầu tiên nó sẽ nhả chân côn để mô tơ của xe chạy chậm lại tránh cho xe bị lật khi qua. Sau đó nó sẽ xoay vô lăng để cho bánh xe rẻ qua 1 bên. Đếm sơ sơ qua là ta có 4 class rồi đấy.
oke. Vậy pattern này là gì. Đơn giản lắm! Bạn thử tưởng tượng trong quá trình bạn code, bạn sẽ phân chia các class khác nhau. Theo thời gian thì sẽ có rất nhiều class khác nhau, và các class này sẽ tương tác qua lại với nhau. Điều này thật sự rất rối rắm.


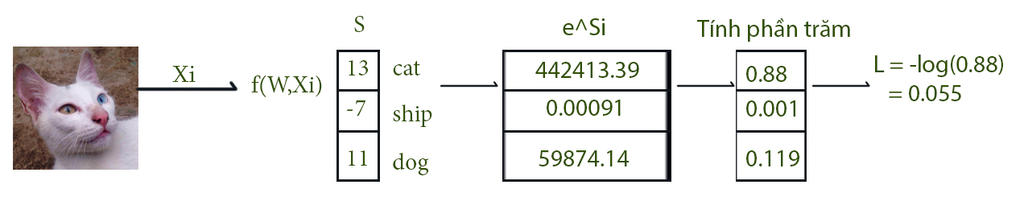
Facade Pattern: tạo ra 1 giao diện cao hơn giúp người dùng dễ dàng sử dụng các giao diện thấp
Okie. Bây giờ ta vào ví dụ và code nào. Giả sử ta đang thiết kế 1 chiếc xe hơi chẳng hạn. Chiếc xe hơi thì có thể rẻ phải rẻ trái. Vậy lúc rẻ thì nó sẽ làm gì?
Đầu tiên nó sẽ nhả chân côn để mô tơ của xe chạy chậm lại tránh cho xe bị lật khi qua. Sau đó nó sẽ xoay vô lăng để cho bánh xe rẻ qua 1 bên. Đếm sơ sơ qua là ta có 4 class rồi đấy.
public class Wheel {
public void turnLeft() {
// re trai
}
public void turnRight() {
// re phai
}
}
public class Steering {
private Wheel wheel = new Wheel();
// xoay vo lang nguoc kim dong ho
public void rotateLeft() {
this.wheel.turnLeft();
}
// xoay vo lang cùng chieu kim dong ho
public void rotateRight() {
this.wheel.turnRight();
}
}
public class Motor{
public void speedUp() {
// tang toc
}
public void slowDown() {
// giam toc
}
}
public class Pedal {
private Motor motor = new Motor();
public void pressDown() {
this.motor.speedUp();
}
public void release() {
this.motor.slowDown();
}
}
Thay vì mỗi lần rẻ trái, chúng ta phải xử lý rối rắm các class trên thì thay vào đó, ta sẽ tạo 1 cái facade Car cho dễ xài.
public class Car{
private Steering steering = new Steering();
private Pedal pedal = new Pedal();
public void turnLeft() {
this.steering.rotateLeft();
this.pedal.release();
}
public void turnRight() {
this.steering.rotateRight();
this.pedal.release();
}
}
Giờ muốn xe rẻ phải thì chỉ cần.
Car car = new Car(); car.turnRight();

























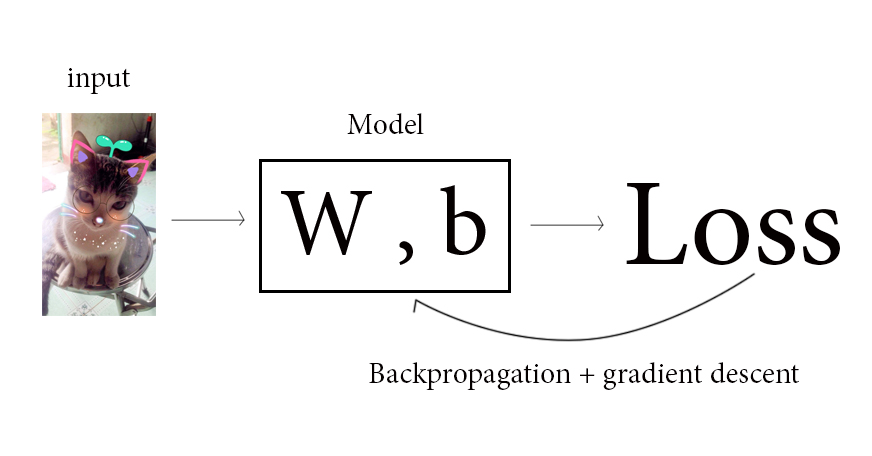
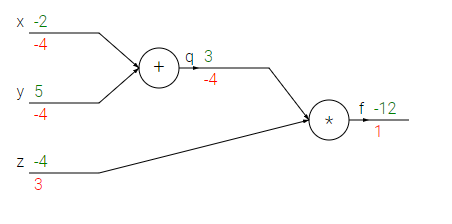
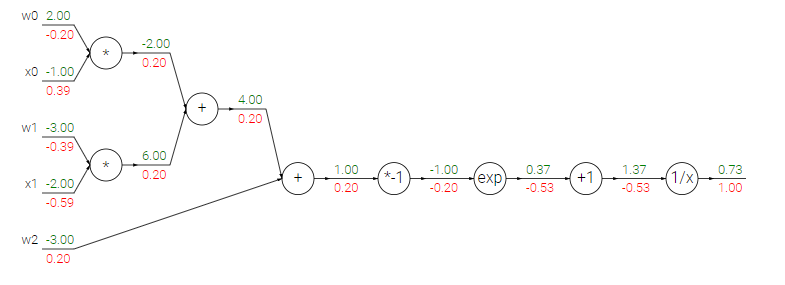
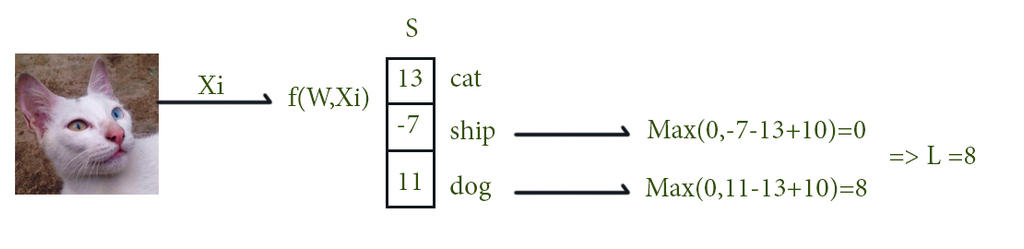
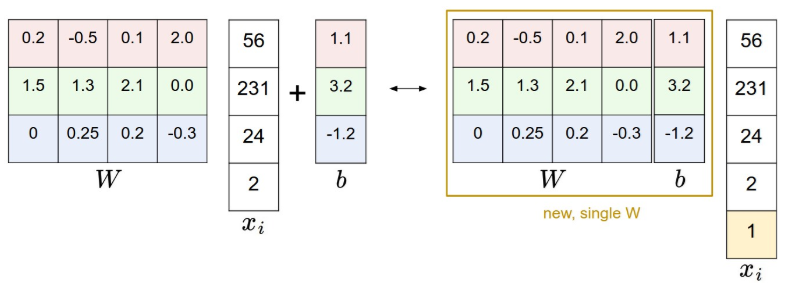
 Chào mừng bạn đến với các bài học Image classification, một trong những bài học thuộc mảng Computer Vision được mình viết trên blog cá nhân. Mong rằng qua những bài học trong series này, bạn sẽ nắm vững được một số kiến thức cơ bản trong việc phân loại hình ảnh sử dụng các phương pháp máy học, để từ đó có thể làm tiền đề cho những ứng dụng sau này của bản thân.
Chào mừng bạn đến với các bài học Image classification, một trong những bài học thuộc mảng Computer Vision được mình viết trên blog cá nhân. Mong rằng qua những bài học trong series này, bạn sẽ nắm vững được một số kiến thức cơ bản trong việc phân loại hình ảnh sử dụng các phương pháp máy học, để từ đó có thể làm tiền đề cho những ứng dụng sau này của bản thân.