Trong bài
Score Function, khi nhìn vào công thức của linear classifier: $f(x_{i},W,b)=Wx_{i}+b$ ta có thể thấy được rằng: $x_{i}$ là đại lượng không thể thay đổi được (vì nó là bức hình chúng ta đưa vào). Nhưng ta có thể thay đổi được các parameters (W và b). Từ đó có ý tưởng, chúng ta sẽ thay đổi các parameters, sao cho với bức ảnh vào, hàm f sẽ cho ra được kết quả dự đoán đúng với các nhãn dán.
Ví dụ với kết quả dự đoán trong bài
Score Function:
Có thể thấy rằng, kết quả đúng (cat) có giá trị thấp hơn so với kết quả sai (Dog, ship). Do đó, nảy sinh một ý tưởng rằng: ta sẽ xây dựng một hàm L nào đó có khả năng đánh giá được độ chính xác của hàm f. Giả sử nếu kết quả của hàm f sai càng nhiều, thì giá trị của hàm L càng cao. Nếu hàm f dự đoán càng đúng, thì hàm L càng thấp. Và hàm L này, người ta gọi nó là
Loss function (hàm độ lỗi).
Loss function (hàm độ lỗi) là hàm có giá trị cao khi kết quả dự đoán của f tệ, và có giá trị thấp khi kết quả dự đoán của f chính xác.
Loss function thì có rất nhiều hàm định nghĩa. Nhưng dưới đây là 2 loại mình sẽ giới thiệu trong bài này:
Multiclass Support Vector Machine loss (SVM)
SVM là hàm được xây dựng sao cho các giá trị của các nhãn đúng phải lớn hơn giá trị của các nhãn sai 1 khoảng Δ nào đó.
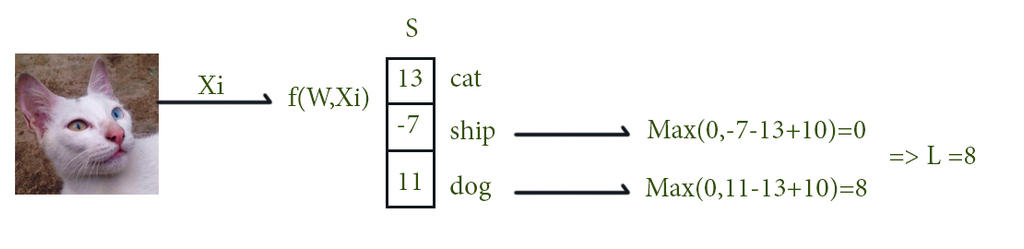
Giả sử với bức hình thứ i, chúng ta có tập pixels $x_{i}$ và nhãn dán $y_{i}$. Score function sẽ nhận giá trị $x_{i}$ và tính toán thông qua hàm $f(x_{i}, W)$ . Giả sử ta quy ước rằng giá trị của nhãn thứ j sau khi được tính toán ra là $s_{j}=f(x_{i},W)_{j}$, thì lúc này hàm SVM cho bức hình thứ I được tính bằng:
$L_{i}=\sum_{j\neq y_{i}}max(0,s_{j}-s_{y_{i}}+\Delta )$
Ví dụ dễ hiểu nhất là: chúng ta có 3 giá trị tương ứng với 3 nhãn dán , sau khi được tính toán bởi hàm f là: s=[13,−7,11]. Và nhãn đúng là nhãn đầu tiên (yi=0) . Giả sử Δ = 10. Svm loss sẽ được tính bằng: Li=max(0,−7−13+10)+max(0,11−13+10)
Ở vế đầu, giá trị là 0, vì max (0,-10) = 0. Ở vế sau, max(0,8) = 8. Vậy nên, tổng loss Li = 0+8 =8. Giá trị này có ý nghĩa độ lỗi của hàm f là 8. Và cũng đúng với tiêu chí của định nghĩa loss function: nếu kết quả f càng tệ thì L có giá trị càng cao. Nói tóm lại là, svm loss sẽ bỏ qua cho giá trị của các nhãn sai bé hơn giá trị nhãn đúng 1 khoảng Δ. Còn nếu không, nó sẽ cộng giá trị sai này vào hàm loss.
Softmax classifier
Bên cạnh SVM loss, một hàm khác được sử dụng phổ biến ko kém là Softmax. Hàm softmax được tính theo công thức:
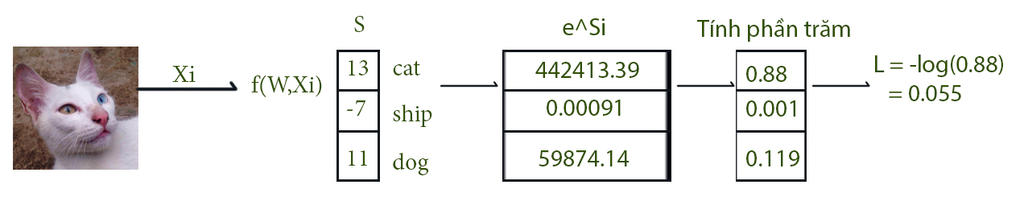
$L_{i} = -log(\frac{e^{f_{yi}}}{\sum _{j}e^{f_{j}}})$
Nhìn thì có vẻ kinh khủng thật. Nhưng mà đi vào ví dụ thì rất dễ hiểu.
Kết quả sau khi được tính từ score function, sẽ được đưa vào hàm $e^{f_{j}}$. Sau đó mỗi giá trị sẽ được tính thành giá trị xác suất. Và cuối cùng, giá trị loss = -log(giá trị của nhãn đúng).
Vậy là xong, tổng kết bài này là bạn hiểu được loss function là gì. Hai hàm svm và softmax là gì. Vậy thôi.


Khi train loss tầm 0. bao nhiêu thì nên dừng ạ
Trả lờiXóaCái này thì theo mình là không có một thang đo cụ thể. Nó còn tùy vào hàm loss của bạn đang xài là hàm gì. Và còn phụ thuộc vào tập dataset của bạn như thế nào. Cứ theo ví dụ đơn giản ở trên, với softmax thì L=0.055, còn với SVM thì L=8, giá trị gấp 145 lần.
XóaMình nghĩ cái cần phải quan tâm là các hàm tính độ chính xác của model. Mỗi khi train xong bạn có thể kiểm thử xem độ chính xác của model là bao nhiêu. Từ đó có thể quyết định bạn có nên train tiếp hay dừng lại.