Mặt khác, với đối tượng đầu vào là bức hình, thì các pixel gần nhau hợp lại sẽ mang những thông tin hữu ích, nhưng neural network thì không khai thác được đặc điểm này. Do đó, có một mạng neural mới, được người ta nghiên cứu sáng tạo ra: đó là convolutional neural network (CNN). Vậy CNN khác với ANN như thế nào? Hiểu một cách nôm na thì CNN không đọc từng pixel riêng lẻ như ANN, mà nó sẽ đọc 1 loạt các pixel gần nhau để đưa vào tính toán. Nhưng để hiểu rõ hơn về cách hoạt động của CNN, chúng ta phải đi vào tìm hiểu từng thành phần cấu tạo nên mạng CNN mới rõ đc. Ở đây chúng ta sẽ tìm hiểu các khái niệm mới như Convolutional Layer, Pooling Layer.
Convolutional Layer:
Convolutional Layer là 1 lớp cực kì quan trọng trong CNN, nó đảm nhận hầu hết chức năng tính toán của mạng.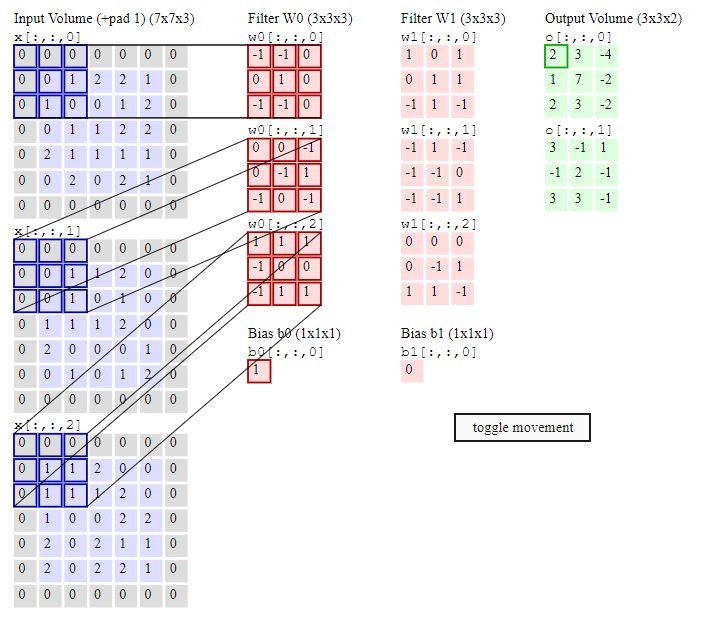
Đầu tiên là khái niệm filter map: thay vì kết nối với từng pixel của hình ảnh đầu vào như ANN, CNN có những tấm filter dùng để áp vào những vùng của bức hình. Các filter map này thực chất là một ma trận 3 chiều gồm các con số. Và điều bạn cần phải cực kì lưu ý là các con số này chính là các parameter cần phải học. Filter map có kích thước dài và rộng là hyperparameter ( hyperparameter là gì thì mình có nói trong bài này) , riêng chiều cao ( mình sẽ gọi là depth - chiều sâu ) của filter map sẽ bằng với depth của lớp trước.
Ví dụ nhìn vào hình ví dụ ở trên, chúng ta có 2 filter map màu hồng là W0 và W1. Mỗi filter map có kích thước 3*3*3. Kích thước dài * rộng ( 3*3 ) là hyperparameter, còn chiều sâu (Depth) sẽ bằng với depth của input volumn, tức là bằng 3.
Stride: như đã nói ở trên, filter map được dùng để trượt lên tấm hình đầu vào, vậy trượt ở đây có nghĩa là như thế nào? Rất đơn giản, chỉ cần dịch filter map theo pixel từ trái sang phải theo từng dòng. Mỗi lần dịch như thế sẽ dựa vào 1 giá trị gọi là stride.
Ví dụ, stride = 1, thì mỗi lần dịch filter map sẽ sang phải 1 pixel, khi hết cạnh biên phải thì xuống 1 dòng và dịch tiếp. Còn nếu stride = 2 thì mỗi lần dịch sẽ sang phải 2 pixel, khi hết cạnh thì xuống 2 dòng.
Padding: người ta sẽ thêm những giá trị 0 bao quanh lớp input. Ví dụ như ở trên hình, lớp input của chúng ta ban đầu có kích thước 5*5*3, nhưng vì giá trị padding = 1, nên được bao thêm 1 lớp 0 bên ngoài. Từ đó, kích thước của lớp input = 7*7*3.
Feature map: feature map thực chất là kết quả sau khi lớp input được filter map quét qua hết. Với mỗi lần filter map áp lên input, sẽ có quá trình tính toán xảy ra. Vậy quá trình tính toán này là gì? Thực chất đó là quá trình nhân 2 ma trận.
Ví dụ như trên hình, khi lớp trên cùng của filter map W0 áp vào lớp trên cùng của input volum, ma trận filtermap w0 3*3 sẽ được nhân với ma trận 3*3 của input sau đó cộng thêm bias=1, và đưa ra kết quả = 2 ở feature map. Kích thước feature map được tính như nào? Mỗi lần 1 filter map trượt hết lên input volum sẽ cho ra 1 lớp của feature map. Vậy nên, depth của feature map sẽ bằng số lượng filter map.
Ví dụ như hình trên, depth của feature map = số lượng filter map = 2. Còn chiều dài và chiều rộng của feature map sẽ được tính bằng công thức: (W + 2P - F)/S +1 . Trong đó, W là kích thước input, P là padding, F là kích thước filter map, S là stride.
Ví dụ với hình, W = 5, P =1, F = 3, S =1 , ta tính được kích thước của feature map là 3.
Ta có thể thấy được, nếu với ANN thông thường, 1 bức hình 7*7*3 như trên sẽ cần có 7*7*3 = 147 parameters (nếu lớp thứ 2 chỉ có 1 neural), nhưng với CNN lại cần ít hơn số parameter từ filter map và số lượng parameter này có thể được chúng ta định lượng.
Pooling layer
Thường giữa các lớp Convolutional Layer với nhau người ta sẽ chèn vào 1 lớp Pooling layer để giảm bớt số lượng parameter lại nếu như đầu vào quá lớn. Có nhiều loại pooling layer, nhưng mình chỉ giới thiệu max pooling.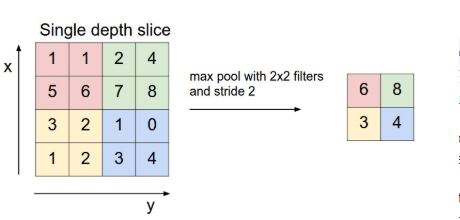

Cảm ơn bài viết khá chi tiết của anh, chúc anh sức khỏe và thành công!
Trả lờiXóaCám ơn bạn đã ghé đọc blog của mình nhé :D
Xóabài viết rất hay, mình đã nắm được cơ bản về Convolutional Network. Hi vọng bạn sẽ tiếp tục viết nhiều bài như thế này nữa để giúp đỡ nhiều bạn sinh viên khác! Chúc bạn sức khoẻ và thành công
Trả lờiXóaCám ơn bạn nhé. Chúc bạn thành công và nhiều sức khoẻ
Xóabạn ơi sao hình của bạn với ví dụ nó không trùng khớp vậy. Ví dụ như hình trên filter map =3 mà kết quả feature map = 2 là sao nhỉ
Trả lờiXóaÀ, ở trên hình số lượng filter map = 2 nhé ( gồm W0 và W1 ). Và mỗi filter map đó lại có độ sâu depth = 3. Chắc bạn bị nhầm chút xíu ở depth của filter map và số lượng filter map rồi ấy
Xóamình trích một đoạn trong bài viết của bạn.
Trả lờiXóa"Kích thước feature map được tính như nào? Mỗi lần 1 filter map trượt hết lên input volum sẽ cho ra 1 lớp của feature map. Vậy nên, depth của feature map sẽ bằng số lượng filter map."
mình muốn hỏi là : tại sao sau mỗi lớp convolution thì thì lại cần nhiều kernel thế, thậm trí số kernel tăng lên rất nhanh?
câu 2 là: Hệ số của convolutional layer là gì?
hiện tại thì kiến thức của mình chưa đủ để trả lời câu hỏi của bạn. Nên bạn chờ mình một thời gian cho việc research nhé.
Xóasau khi hỏi bạn bè và dành một khoảng thời gian để research, mình xin giải đáp câu hỏi của bạn.
Xóacâu 1: Kernel càng nhiều thì depth của feature map càng lớn. Mỗi feature map được xem như là 1 characteristic của bức ảnh. Tức là càng nhiều kernel thì sẽ càng thể hiện được nhiều thông tin của 1 đối tượng đầu vào.
Câu 2: mình vẫn chưa hiểu hệ số convolutional layer là gì. Nếu ý bạn hệ số là weights, thì trong cnn, weights chính là các con số trên kernel.
còn viết bài nữa không tác giả ơi. Bạn viết rất dễ hiểu
Trả lờiXóacái series image classification này mình hoàn thành rồi nên sẽ không có bài mới ạ. Nếu có thì chắc sẽ là một series khác thôi bạn nha. ^^ cám ơn bạn đã ghé thăm blog của mình nha
Xóa